This blog briefly reviews the pre-training embeddings and models in NLP.
Pre-Trained Embeddings
Word2Vec
1 | T. Mikolov, et al., 2013. Efficient Estimation of Word Representations in Vector Space. arXiv preprint arXiv:1301.3781. |
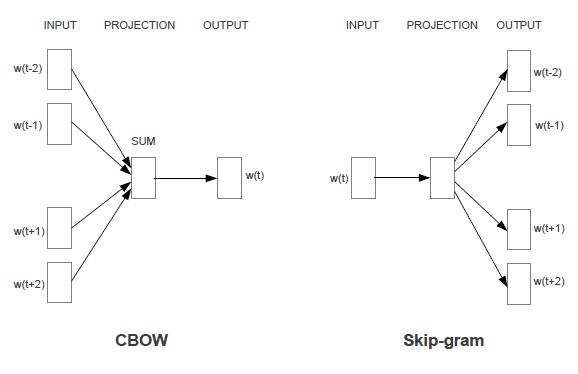
Continuous Bag-of-Words Model
Given a sequence of words $w_1, w_2, w_3, \cdots, w_T$, maximize the average log probability:
where
where $v_i$ and $v’_i$ are “input” and “output” vector representations of word $i$, and $W$ is the vocabulary size.
Continuous Skip-Gram Model
Given a sequence of words $w_1, w_2, w_3, \cdots, w_T$, maximize the average log probability:
where the basic formula of $p \left( w_{t+j} | w_t \right)$ can be:
Hierarchical Softmax
Negative Sampling
GloVe: Global Vectors for Word Representation
1 | J. Pennington, R. Socher, C. D. Manning, 2014. GloVe: Global vectors for word representation. EMNLP 2014. |
The embeddings are trained only on the non-zero elements in a word-word co-occurrence matrix.
Let the word-word co-occurrence matrix be denoted by $X$, whose entries $X_{ij}$ tabulate the number of times word $j$ occurs in the context of word $i$.
Let $X_i = \sum_k X_{ik}$ be the number of times any word appears in the context of word $i$.
Let $P_{ij} = P(j|i) = X_{ij} / X_{i}$ be the probability that word $j$ appear in the context of word $i$.
How certain aspects of meaning can be extracted from co-occurance probabilities?
Take $i = ice$ and $j = steam$, then:
- For words $k$ related to $ice$ but not $steam$ (e.g., $k = solid$), the ratio $P_{ik}/P_{jk}$ should be large;
- For words $k$ related to $steam$ but not $ice$ (e.g., $k = gas$), the ratio $P_{ik}/P_{jk}$ should be small;
- For words $k$ related to both (e.g., $k = water$) or neither (e.g., $k = fashion$), the ratio $P_{ik}/P_{jk}$ should be close to one.
Hence, compared to the raw probabilities, the ratio is better able to distinguish relevant words ($solid$ and $gas$) from irrelevant words ($water$ and $fashion$).
The GloVe Model
Note that the ratio $P_{ik}/P_{jk}$ depends on three words $i$, $j$ and $k$, so the most general model takes the form:
where $w \in \mathbb{R}^d$ are word vectors, and $\tilde{w} \in \mathbb{R}^d$ are separate context word vectors.
To only consider vector differences, the equation becomes:
To keep the linear structure of vector space, the equation becomes:
Require that $F = \exp$, then:
Then:
Then:
Absorb $\log \left( X_i \right)$ to a bias $b_i$, and add another bias $\tilde{b}_k$ for symmetry:
A weighted least squares regression model to estimate the parameters:
where $V$ is the vocabulary size and $f$ is the weighting function.
Training Details
Train the model using AdaGrad, stochastically sampling nonzero elements from $X$.
FastText
1 | P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, 2016. Enriching word vectors with subword information. ACL 2017. |
Each word is represented as a bag of character n-grams.
Each character n-gram is associated to a vector representation, and a word is represented as the sum of the vector representations of its character n-grams.
Pre-Trained Models
CoVe: Learned in Translation: Contextualized Word Vectors
1 | B. McCann, et al., 2017. Learned in Translation: ContextualizedWord Vectors. NIPS 2017. |
Train an encoder for a large NLP task, and transfer the trained encoder to other NLP tasks.
Specifically, McCann et al. (2017) train an attentional seq2seq model for machine translation, and use the LSTM-based encoder (which is a common component in NLP tasks) to transfer to other tasks.
The largest machine translation dataset is WMT 2017, consisting roughly 7M sentence pairs.
ELMo
1 | M. E. Peters, et al., 2018. Deep contextualized word representations. ACL 2018. |
Bidirectional language models
Given a sequence of words $(w_1, w_2, w_3, \cdots, w_T)$, a forward language model (forward LM) computes the probability of the sequence by modeling the word $w_k$ given the history $(w_1, w_2, \cdots, w_{k-1})$:
And a backward LM computes:
With a bidirectional LSTM, the log likelihood is:
where $\Theta_x$ is the token representation layer, and $\Theta_s$ is the softmax layer.
ELMo representations
Combine the outputs of different LSTM layers (including the token representation layer) as ELMo representations.
Flair
1 | A. Akbik, et al., 2018. Contextual String Embeddings for Sequence Labeling. COLING 2018. |
Character-level language modeling: An bidirectional LSTM, each LSTM is trained to predict the next character given the history characters.
BERT
1 | J. Devlin, et al., 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL-HLT 2019. |
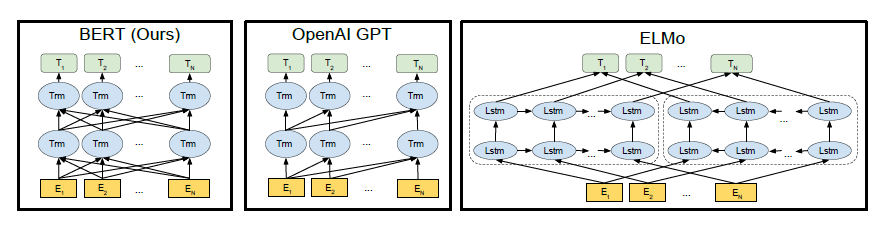
Model Architecture
Transformer encoder: Transformer blocks attend to both left and right contexts.
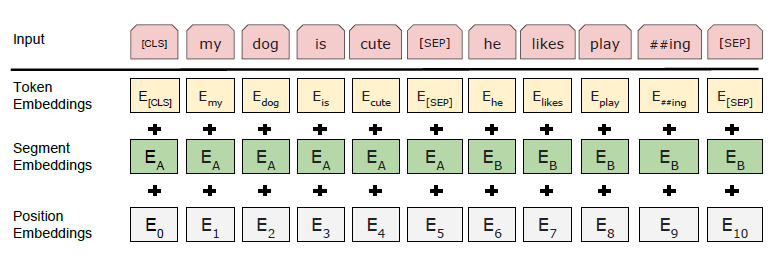
Input Representation
- WordPiece Embeddings: Split word pieces are denoted with ##.
- Trainable positional embeddings with supported sequence lengths up to 512 tokens.
- The first token of every sequence is always
[CLS], which is used as the aggregate sequence representation
for classification tasks. - Sentence pairs are packed into single sequence.
- The two sentences are seperated with
[SEP]. - Add a trainable sentence A embedding to every token of the first sentence.
- Add a trainable sentence B embedding to every token of the second sentence.
- For single-sentence inputs, only use the sentence A embeddings.
- The two sentences are seperated with
Pre-Training Task #1: Masked LM (MLM)
Masked LM: Randomly mask some percentage of the input tokens, and use other tokens to predict the masked tokens. Or referred as Cloze Task.
Specifically, 15% tokens are masked, being replaced with a [MASK] token. However, this creates a mismatch between pre-training and fine-tuning, since the [MASK] token is never seen during fine-tuning. Hence, the data generator chooses 15% random tokens and performs:
- 80% of the time: Replace with
[MASK]token; - 10% of the time: Replace with a random word;
- 10% of the time: Keep the word unchanged.
Pre-Training Task #2: Next Sentence Prediction (NSP)
Many downstream tasks such as Question Answering (QA) and Natural Language Inference (NLI) are based on understanding the relationship between two text sentences.
Next Sentence Prediction: Choose the sentences A and B for each pretraining example
- 50% of the time: B is the actual next sentence that follows A;
- 50% of the time: B is a random sentence from the corpus.
The objective is to predict whether B is actually following A.
Pre-Training Procedure
- Batch size: 256 sequences (256 * 512 = 128,000 tokens)
- Training steps: 1,000,000
- Optimization
- Adam with learning rate of 1e-4, L2 weight decay of 0.01
- Learning rate warmup over the first 10,000 steps, and linear decay of the learning rate
- Dropout: 0.1 on all layers
Fine-Tuning Procedure
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
GPT (Generative Pre-Training)
1 | A. Radford, et al., 2018. Improving Language Understanding by Generative Pre-Training. |
Model Architecture
Transformer decoder: Transformer blocks attend to only left contexts.
Unsupervised Pre-Training
Given an unlabeled sequence of tokens $\mathcal{U} = (u_1, u_2, u_3, \cdots, u_T)$, use a standard language modeling objective to maximize the following likelihood:
where $c$ is the context window size, $\Theta$ represents the model parameters.
Specifically,
where $U = (u_{-k}, \dots, u_{-1})$ is the context vector of tokens, $n$ is the number of layers, $W_e$ is the token embedding matrix, and $W_p$ is the position embedding matrix.
Supervised Fine-Tuning
Given a labeled dataset $\mathcal{C}$, consisting sequences of input tokens $(x^1, x^2, x^3, \cdots, x^T)$, along with labels $y$, maximize:
Include language modeling as an auxiliary objective:
Task-Specific Input Transformations
Introduce special tokens for downstream tasks with structured inputs like textual entailment or QA.
- Randomly initialized start token
<s>and end token<e>. - Delimiter token
$.
Zero-Shot Behaviors
Zero-Shot Evaluation: Use the pre-trained generative model to perform tasks without supervised finetuning:
- CoLA (Linguistic acceptability): Scored as the average token log-probability the generative model assigns and predictions are made by thresholding.
- SST-2 (Sentiment analysis): Append the token
veryto each example, restrict the language model’s output distribution to only the wordspositiveandnegative, and guess the token it assigns higher probability to as the prediction. - RACE (Question answering): Pick the answer the generative model assigns the highest average token log-probability when conditioned on the document and question.
- DPRD (Winograd schemas): Replace the definite pronoun with the two possible referrents and predict the resolution that the generative model assigns higher average token log-probability to the rest of the sequence after the substitution.
GPT-2
1 | A. Radford, et al., 2019. Language Models are Unsupervised Multitask Learners. |
Language models can learn multiple NLP tasks without any explicit supervision.
- When conditioned on a document plus questions, the answers generated by GPT-2 reach 55 F1 on the CoQA dataset - matching or exceeding the performance of baseline systems without using the 127,000+ training examples.
Task Conditioning
A single-task model: estimating a conditional distribution $p (output | input)$
A multi-task model: conditioning on both input and task, i.e., modeling $p (output | input, task)$
- Task conditioning implemented at architectural level
- Task conditioning implemented at algorithmic level
- Specify task, input and output as sequence of symbols
- Machine translation:
(translate to french, english text, french text) - Reading comprehension:
(answer the question, document, question, answer)
- Machine translation:
Training Dataset
Common Crawl results in significant data quality issues.
Scrape all outbound links from Reddit, which can be thought of as a heuristic indicator for whether other users found the link interesting, educational, or just funny.
Input Representation
Byte Pair Encoding (BPE): Byte-level version of BPE.
Experiments
- Children’s Book Test (Cloze): Compute the probability of each choice in the sentence, and predict the one with the highest probability.
- CoQA (Reading comprehension): Greedy decode from GPT-2 when conditioned on the document, the history of conversation (such as “
Why?“), and a final tokenA. - Summarization: Add the text
TL;DR. - Translation: Condition the language model on a context of example pairs of the formart
english sentence = french sentenceand then after the final prompt ofenglish sentence =, sample from the model with greedy decoding.- Do good at French-English translation, while bad at English-French translation.
GPT-3
1 | T. B. Brown, et al., 2020. Language Models are Few-Shot Learners. |
In-Context Learning
- Fine-Tuning: Update the weights of LM by training on a supervised dataset specific to the desired task.
- Few-Shot: No weights are updated; The LM is given a few demonstrations of the desired task at inference time as conditioning.
- One-Shot: No weights are updated; The LM is given ONE demonstration.
- Zero-Shot: No weights are updated; The LM is given a natural language description of the desired task.